推荐系统
推荐系统
推荐系统本质上是一个信息过滤系统,通常分为:召回、排序、重排序。每个环节逐层过滤,从海量的物料库中筛选出几十个用户可能感兴趣的物品推荐给用户
整体架构
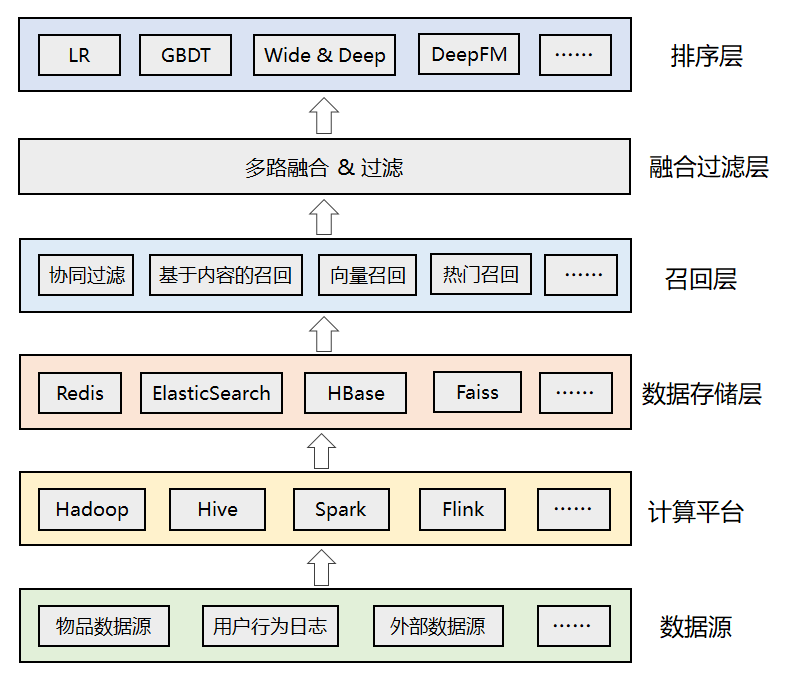
- 数据源:推荐算法所依赖的各种数据源,包括物品数据、用户数据、行为日志、其他可利用的业务数据、甚至公司外部的数据;
- 计算平台:负责对底层的各种异构数据进行清洗、加工,离线计算和实时计算;
- 数据存储层:存储计算平台处理后的数据,根据需要可落地到不同的存储系统中,比如Redis中可以存储用户特征和用户画像数据,ES中可以用来索引物品数据,Faiss中可以存储用户或者物品的embedding向量等;
- 召回层:包括各种推荐策略或者算法,比如经典的协同过滤,基于内容的召回,基于向量的召回,用于托底的热门推荐等。为了应对线上高并发的流量,召回结果通常会预计算好,建立好倒排索引后存入缓存中;
- 融合过滤层:触发多路召回,由于召回层的每个召回源都会返回一个候选集,因此这一层需要进行融合和过滤;
- 排序层:利用机器学习或者深度学习模型,以及更丰富的特征进行重排序,筛选出更小、更精准的推荐集合返回给上层业务。
从数据存储层到召回层、再到融合过滤层和排序层,候选集逐层减少,但是精准性要求越来越高,因此也带来了计算复杂度的逐层增加,这个便是推荐系统的最大挑战。
推荐引擎的核心
对于推荐引擎来说,最核心的部分主要是两块:特征和算法。
graph LR A[推荐引擎]-->Feature[特征] A[推荐引擎]-->Algo[算法] Algo-->召回算法 召回算法-->协同过滤 召回算法-->基于内容召回 召回算法-->基于向量召回 Algo-->排序算法 排序算法-->LR 排序算法-->GBDT 排序算法-->Wide&Deep Feature-->offline(离线特征) Feature-->realtime(实时特征) offline-->Spark(Spark) offline-->Redis(Redis) realtime-->Kafka(Kafka) realtime-->Flink(Flink) realtime-->Redis2(Redis)
特征计算
特征计算由于数据量大,通常采用大数据的离线和实时处理技术,像Spark、Flink等。然后将计算结果保存在Redis或者其他存储系统中(比如HBase、MongoDB或者ES),供召回和排序模块使用
召回算法
从海量数据中快速获取一批候选数据,要求是快和尽可能的准。这一层通常有丰富的策略和算法,用来确保多样性,为了更好的推荐效果,某些算法也会做成近实时的。
排序算法
对多路召回的候选集进行精细化排序。它会利用物品、用户以及它们之间的交叉特征,然后通过复杂的机器学习或者深度学习模型进行打分排序,这一层的特点是计算复杂但是结果更精准。
协同过滤(Collaborative Filtering, CF)
协同过滤算法的核心就是「找相似」,它基于用户的历史行为(浏览、收藏、评论等),去发现用户对物品的喜好,并对喜好进行度量和打分,最终筛选出推荐集合。
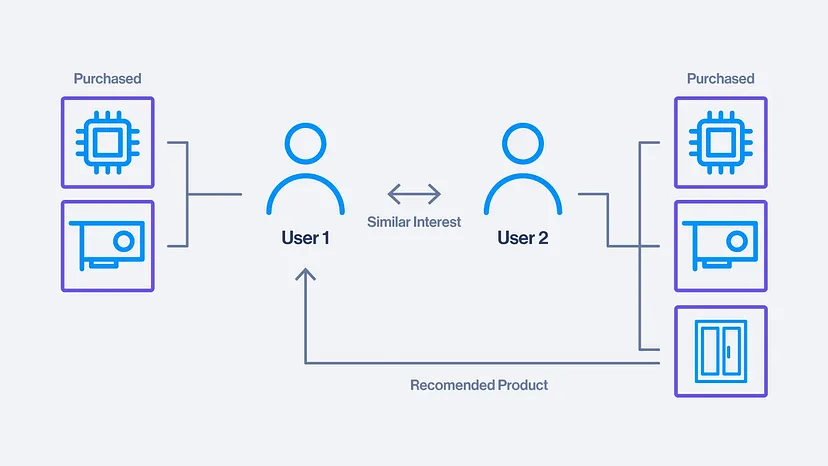
基于用户的协同过滤(User-CF)
核心是找相似的人。
如果用户A和B的购买记录中包含许多相同的物品,那么认为二人是相似的,就可以将一人购买过的物品推荐给另一人:
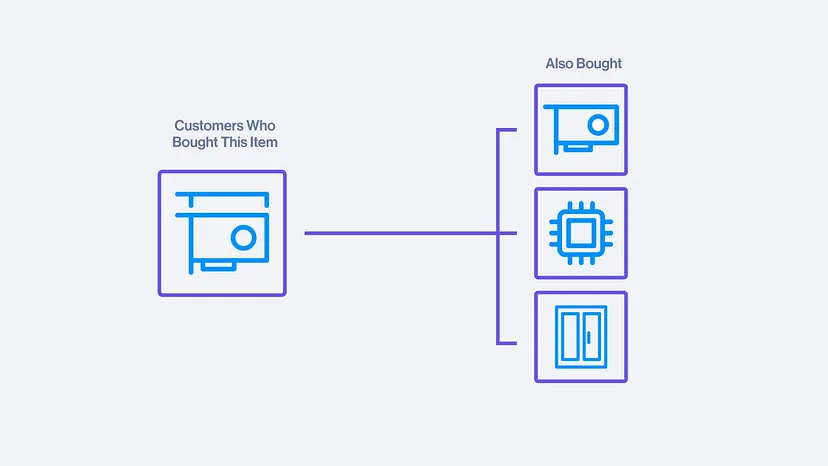
基于物品的协同过滤(Item-CF)
核心是找相似的物品。如果两物品都被相同的人购买过,则两者相似,当其中一物品被购买时,推荐另一物品
相似度的度量
Jaccard相似系数
衡量两个集合相似度的一种指标。两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的Jaccard相似系数,用符号$J(A,B)$表示。
余弦相似度
使用两向量间夹角余弦值度量相似度
闵可夫斯基距离(Minkowski Distance)
The Minkowski distance or Minkowski metric is a metric) in a normed vector space which can be considered as a generalization of both the Euclidean distance and the Manhattan distance.
通过改变$p$可以得到曼哈顿距离、欧氏距离、切比雪夫距离等的表达式,不再赘述。
Pearson相关系数
使用用户平均分对个独立评分进行修正, 减少了用户评分偏置的影响。
此系数实际是每个向量先减去了它的平均值, 然后计算余弦相似度, 其中$R_{i,p}$代表用户$i$对物品$p$的评分。$\bar{R}_i$代表用户$i$ 对所有物品的平均评分,$P$代表所有物品的集合,$p$ 表示某个物品。
总体的来说,欧式距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。协同滤波中常用余弦相似度或Pearson相关系数

