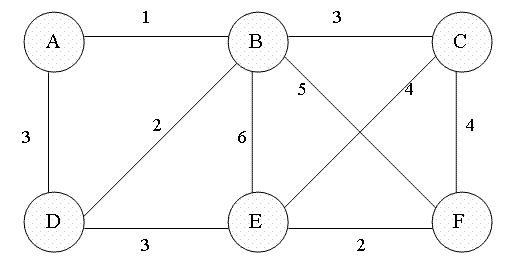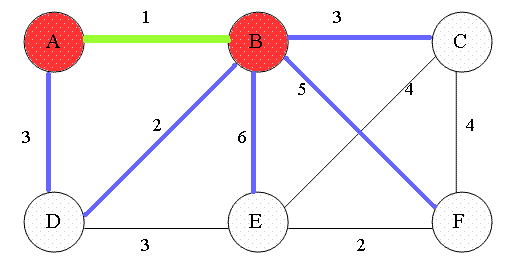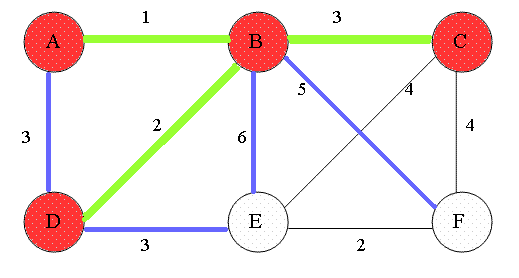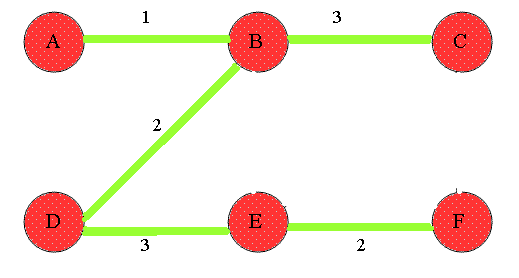
最短路径算法 Dijkstra 伟大,无需多言。实际上Dijkstra算法就是维护了一个dist数组,定义dist[i]表示起点到i号节点的最短距离值。这样,从起点出发,更新当前邻居节点的距离。由于在初始化dist数组时会将除起点外所有节点设置为不可达(INT_MAX),因此每次更新dist数组时,最小的距离一定是可达的。
每次更新dist数组,即寻找当前距离最小的节点,然后遍历其邻居节点。
方程为:
1 2 3 4 if (dist[node] + weight < dist[neighbor]) { dist[neighbor] = dist[node] + weight; pq.push({dist[neighbor], neighbor}); }
这里可以看到使用了优先队列(本质上是二叉最小堆)来优化Dijkstra算法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <iostream> #include <vector> #include <queue> #include <limits> using std::cout;using std::cin;using std::pair;using std::vector;using std::priority_queue;using std::endl;typedef pair<int , int > pii; const int INF = INT_MAX; int dijkstra (const vector<vector<pii>>& graph, int n, int start, int end) vector<int > dist (n + 1 , INF) ; dist[start] = 0 ; priority_queue<pii, vector<pii>, std::greater<pii>> pq; pq.push ({0 , start}); while (!pq.empty ()) { int d = pq.top ().first; int node = pq.top ().second; pq.pop (); if (d > dist[node]) continue ; for (auto & edge : graph[node]) { int neighbor = edge.first; int weight = edge.second; if (dist[node] + weight < dist[neighbor]) { dist[neighbor] = dist[node] + weight; pq.push ({dist[neighbor], neighbor}); } } } if (dist[end] == INF) { return -1 ; } else { return dist[end]; } } int main () int n, m; cin >> n >> m; vector<vector<pii>> graph (n + 1 ); for (int i = 0 ; i < m; i++) { int x, y, z; cin >> x >> y >> z; graph[x].push_back ({y, z}); } int shortest_distance = dijkstra (graph, n, 1 , n); cout << shortest_distance << endl; return 0 ; }
Bellman-Ford Dijkstra无法解决有负权边的图,需要使用Bellman-Ford算法每次对每个边进行遍历,判断是否有更优路径。这个操作被称为松弛操作,即判断d[u]+length[u->v] < d[v]。如果为真,则d[u]+length[u->v]覆盖d[v]。松弛操作最多为V-1次,也就是节点数减一。松弛操作的次数也代表路径边数可能的最大值。时间复杂度为$\mathcal{O}(VE)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <iostream> #include <vector> #include <climits> #include <utility> using namespace std;typedef pair<int , int > pii; const int INF = INT_MAX; int bellmanFord (const vector<vector<pii>>& graph, int n, int start, int end, int k) vector<int > dist (n + 1 , INF) ; dist[start] = 0 ; for (int i = 0 ; i < k; ++i) { vector<int > temp = dist; for (int u = 1 ; u <= n; ++u) { for (const pii& edge : graph[u]) { int v = edge.first; int weight = edge.second; if (dist[u] != INF && dist[u] + weight < temp[v]) { temp[v] = dist[u] + weight; } } } dist = temp; } if (dist[end] == INF) { return INF; } else { return dist[end]; } } int main () int n, m, k; cin >> n >> m >> k; vector<vector<pii>> graph (n + 1 ); for (int i = 0 ; i < m; ++i) { int x, y, z; cin >> x >> y >> z; graph[x].push_back ({y, z}); } int ans = bellmanFord (graph, n, 1 , n, k); if (ans == INF) { cout << "impossible" << endl; } else { cout << ans << endl; } return 0 ; }
SPFA Bellman-Ford算法的思路很简洁,但是时间复杂度为$\mathcal{O}(VE)$,很容易超时。因为其每轮操作都需要遍历所有的边,注定有大量重复的无意义操作。SPFA便是维护一个队列对Bellman-Ford算法进行优化,一般的时间复杂度为$\mathcal{O}(kE)$。当图中有源点可达的负环时退化为$\mathcal{O}(VE)$
优化的思路是:只有当某个顶点u的d[u]值改变时,从它出发的边的邻接点v的d[v]值才有可能被改变。通过维护一个队列,每次将队首顶点u取出,遍历所有边u->v进行松弛操作,如果d[u]+length[u->v] < d[v],则d[u]+length[u->v]覆盖d[v],此时如果v不在队列中,则将v加入队列。循环直到队列为空。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <iostream> #include <vector> #include <queue> #include <climits> #include <utility> using namespace std;typedef pair<int , int > pii; const int INF = INT_MAX; int spfa (const vector<vector<pii>>& graph, int n, int start, int end) vector<int > dist (n + 1 , INF) ; vector<bool > inQueue (n + 1 , false ) ; queue<int > q; dist[start] = 0 ; q.push (start); inQueue[start] = true ; while (!q.empty ()) { int u = q.front (); q.pop (); inQueue[u] = false ; for (const pii& edge : graph[u]) { int v = edge.first; int weight = edge.second; if (dist[u] + weight < dist[v]) { dist[v] = dist[u] + weight; if (!inQueue[v]) { q.push (v); inQueue[v] = true ; } } } } return dist[end]; } int main () int n, m; cin >> n >> m; vector<vector<pii>> graph (n + 1 ); for (int i = 0 ; i < m; ++i) { int x, y, z; cin >> x >> y >> z; graph[x].push_back ({y, z}); } int ans = spfa (graph, n, 1 , n); if (ans == INF) { cout << "impossible" << endl; } else { cout << ans << endl; } return 0 ; }
Floyd Floyd算法用于解决全源最短路径问题。其时间复杂度为$\mathcal{O}(V^3)$
很显然图的顶点数V不可能过大(一般不超过200),因此可以使用邻接矩阵而非邻接表来存储图。
Floyd的思想类似Bellman-Ford的松弛操作,即:
如果存在顶点k,使得以k作为从i到j途径的中介点时可以缩短后两者的当前最短路径距离,则使用k来更新i到j的路径。也就是:
1 2 if (distance[i][k]+dis[k][j] < distance[i][j]) distance[i][j] = distance[i][k] + distance[k][j];
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <vector> #include <algorithm> using namespace std ; const int INF = 1e9 ; int main () { int n, m, k; cin >> n >> m >> k; vector <vector <int >> dist(n, vector <int >(n, INF)); for (int i = 0 ; i < n; i++) { dist[i][i] = 0 ; } for (int i = 0 ; i < m; i++) { int x, y, z; cin >> x >> y >> z; x--; y--; dist[x][y] = min(dist[x][y], z); } for (int k = 0 ; k < n; k++) { for (int i = 0 ; i < n; i++) { for (int j = 0 ; j < n; j++) { if (dist[i][k] < INF && dist[k][j] < INF) { dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j]); } } } } for (int i = 0 ; i < k; i++) { int x, y; cin >> x >> y; x--; y--; if (dist[x][y] == INF) { cout << "impossible" << endl ; } else { cout << dist[x][y] << endl ; } } return 0 ; }
MST Prim Prim实质上是一种贪心的算法,从一个给定起点出发,每次遍历自身邻居,找到当前最短路径的点,延伸生成树。适用于稠密图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <iostream> #include <vector> #include <queue> #include <climits> using namespace std ; struct Edge { int v, w; Edge(int _v, int _w) : v(_v), w(_w) {} }; int main () { int n, m; cin >> n >> m; vector <vector <Edge>> graph(n + 1 ); for (int i = 0 ; i < m; ++i) { int u, v, w; cin >> u >> v >> w; graph[u].emplace_back(v, w); graph[v].emplace_back(u, w); } vector <bool > visited (n + 1 , false ) ; vector <int > minCost (n + 1 , INT_MAX) ; priority_queue <pair <int , int >, vector <pair <int , int >>, greater<pair <int , int >>> pq; int start = 1 ; minCost[start] = 0 ; pq.push({0 , start}); int totalCost = 0 ; while (!pq.empty()) { int u = pq.top().second; int minDist = pq.top().first; pq.pop(); if (visited[u]) continue ; visited[u] = true ; totalCost += minDist; for (const Edge& e : graph[u]) { int v = e.v; int w = e.w; if (!visited[v] && w < minCost[v]) { minCost[v] = w; pq.push({w, v}); } } } bool possible = true ; for (int i = 1 ; i <= n; ++i) { if (!visited[i]) { possible = false ; break ; } } if (possible) cout << totalCost << endl ; else cout << "impossible" << endl ; return 0 ; }
Kruscal 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <vector> #include <algorithm> using namespace std ; struct Edge { int u, v, w; bool operator<(const Edge& other) const { return w < other.w; } }; vector <int > parent;int find (int x) { return parent[x] == x ? x : parent[x] = find(parent[x]); } void unite (int x, int y) { parent[find(x)] = find(y); } int main () { int n, m; cin >> n >> m; vector <Edge> edges (m) ; for (int i = 0 ; i < m; ++i) { cin >> edges[i].u >> edges[i].v >> edges[i].w; } sort(edges.begin(), edges.end()); parent.resize(n + 1 ); for (int i = 1 ; i <= n; ++i) { parent[i] = i; } int count = 0 ; int sum = 0 ; for (const auto & e : edges) { if (find(e.u) != find(e.v)) { unite(e.u, e.v); sum += e.w; ++count; } } if (count == n - 1 ) { cout << sum << endl ; } else { cout << "impossible" << endl ; } return 0 ; }
Bipartite Graph Staining 染色法判定二分图实际上是对图的每个未染色的点进行一次BFS,将起始节点染成一种颜色,入队;遍历队列,每次取出队首顶点,检查其所有邻接顶点:
如果未染色,则染成不同的颜色并入队
如果已染色并且颜色与邻接顶点相同,则该图不是二分图,否则继续检查下一个顶点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <iostream> #include <vector> #include <queue> using namespace std ; const int N = 1e5 + 10 ; vector <int > G[N]; int color[N]; bool isBipartite (int n) { for (int i = 1 ; i <= n; ++i) { if (color[i] == 0 ) { queue <int > q; q.push(i); color[i] = 1 ; while (!q.empty()) { int u = q.front(); q.pop(); for (int v : G[u]) { if (color[v] == 0 ) { color[v] = -color[u]; q.push(v); } else if (color[v] == color[u]) { return false ; } } } } } return true ; } int main () { int n, m; cin >> n >> m; for (int i = 0 ; i < m; ++i) { int u, v; cin >> u >> v; G[u].push_back(v); G[v].push_back(u); } cout << (isBipartite(n) ? "Yes" : "No" ) << endl ; return 0 ; }
Hungary algorithm 匈牙利算法用于求解二分图的最大匹配数。与染色法不同,该算法是基于DFS的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <iostream> #include <vector> #include <cstring> using namespace std ; const int N = 1e3 + 10 ; vector <int > G[N]; int match[N]; bool used[N]; bool dfs (int u) { for (int v : G[u]) { if (!used[v]) { used[v] = true ; if (match[v] == 0 || dfs(match[v])) { match[v] = u; return true ; } } } return false ; } int bipartiteMatching (int n1, int n2) { int result = 0 ; memset (match, 0 , sizeof (match)); for (int i = 1 ; i <= n1; ++i) { memset (used, 0 , sizeof (used)); if (dfs(i)) { ++result; } } return result; } int main () { int n1, n2, m; cin >> n1 >> n2 >> m; for (int i = 0 ; i < m; ++i) { int u, v; cin >> u >> v; G[u].push_back(v); } cout << bipartiteMatching(n1, n2) << endl ; return 0 ; }